Intersection of Two Unsorted Arrays
by Zoran Horvat
Problem Statement
Given two unsorted arrays containing integer numbers, write a function that returns the third array or ot suitable collection (e.g. a list) which is the intersection of the two arrays. This means that the resulting array should only contain elements that appear in both input arrays. Order of elements in the resulting array is irrelevant.
Example: The first array is 3, 1, 2, 3, 4, 2, 3. The second array is 2, 3, 6, 2, 5, 2, 2, 3. Intersection of these two arrays is 3, 2, 3, 2.
Problem Analysis
In this task we need to traverse through two arrays, initially unsorted, and find matching elements that appear in both arrays. We do not want to presume any particular traversal, but it would certainly be beneficial if number of times that we access array elements is kept low. On the other hand, space required to run the algorithm should also be reduced, if possible.
Indexing Solution
Let’s start cracking the problem by providing some very simple solution. For example, we could index somehow one of the arrays, then iterate through the other array. Each element that is found in the index is pushed to the output and simultaneously removed from the index. Critical characteristics of this solution are then space taken by the index and time it takes to insert, find and remove items from it. Most of the data structures that could be used here take space proportional to number of items stored. In terms of time, hash table is probably the best option. It requires O(1) time to insert, find and remove items. If array lengths are n and m, it takes O(n) total time to index one array. Pass through the second array, including finding elements in the hash table would take O(m) time. Finally, removing elements that are found in the hash table would take O(min(m, n)) time in worst case. From structure size point of view, it makes sense to index the shorter of the arrays. Bottom line is that this solution requires O(n+m) time and O(min(n, m)) space. Here is the pseudocode which implements this solution:
function Intersection(a, b, n, m)
-- a - array
-- b - array
-- n - length of a
-- m - length of b
begin
-- intersection - resulting array
if (n > m)
intersection = Intersection(b, a, m, n);
else
begin
-- hash – hash table
for i = 1 to n
if hash contains a[i] then
hash[a[i]] = hash[a[i]] + 1
else
add mapping a[i] -> 1 to hash
for j = 1 to m
begin
if hash contains b[i] AND hash[b[i]] > 1 then
append b[i] to intersection
hash[b[i]] = hash[b[i]] - 1
else if hash contains b[i] AND hash[b[i]] = 0 then
append b[i] to intersection
remove b[i] from hash
end
end
return intersection;
end
Note that hash table in this implementation is used as a multiset. Each element added to the hash table is associated with its count. When element is first added to the hash table, its count is one. Each next time, the count for the element is incremented by one. Similarly, whenever an element is found in the hash table, its count is decremented by one. Should the count fall down to zero for any element, corresponding entry is removed from the hash table.
Quality of this solution is that it solves the problem in time proportional to just iterating through both arrays - hardly that we could expect anything more efficient than that. However, with memory consumption proportional to size of the array, there is plenty of room for improvements.
Brute Force Solution
In order to reduce memory footprint we could now search for an in-place solution. One very simple algorithm would be to compare each element of one array with each element of the other array. Time complexity of this solution is O(n*m), which is much worse than linear time provided by the hashing solution. But space consumption is now reduced to O(1). Here is the pseudocode:
function Intersection(a, b, n, m, out k)
-- a – array
-- b – array
-- n – length of a
-- m – length of b
-- k – on output contains length of intersection
begin
k = 0;
for i = 1 to n
begin
for j = k + 1 to m
begin
if a[i] = b[j] then
begin
k = k + 1
tmp = b[k]
b[k] = b[j]
b[j] = tmp
j = m -- exit the loop
end
end
end
intersection = empty array
if k > 0 then
intersection = subarray(b, 1, k) -- first k elements
return intersection
end
There are a couple of details in this function which require explanations. When element is found in the array, it is moved towards the beginning of the array and observed start of the array is increased by one. In this way, we guarantee that the same element is not going to be found again. But when that process completes, we note that elements at the beginning of the array are the intersection we were looking for.
Sorting Solution
We could now try to enhance the in-place intersecting algorithm presented in previous section. Our goal is to keep space requirement at O(1), but to reduce time complexity below quadratic time. One way to proceed is to sort both arrays and then to iterate through them in parallel, extracting equal elements along the way. Here is the pseudocode which does precisely that.
function] Intersection(a, b, n, m)
-- a - array
-- b - array
-- n - length of a
-- m - length of b
begin
sort a
sort b
i = 1
k = 1
intersection - empty array
while i <= n AND j <= m
begin
if a[i] = b[i] then
append a[i] to intersection
i = i + 1
j = j + 1
else if a[i] < b[j] then
i = i + 1
else
j = j + 1
end
return intersection
end
This solution possesses several positive properties. First of all, it is more efficient: it takes O(nlogn) time to sort array a, O(mlogm) time to sort array b and O(n+m) time to iterate through both arrays and produce the resulting array. Total execution time is then O(nlogn+mlogm). Space required is still O(1).
Drawback of this solution is that sorting both arrays completely might be an overkill. Consider arrays [1000, 999, 998, ..., 1] and [2000, 1999, 1998, ..., 1001]. We could sort these arrays in roughly 20,000 comparisons (2*1,000*log2(1,000)). But it is obvious that intersection of these two arrays is an empty set, simply because maximum value from the first array is smaller than the minimum value from the second array. Since minimum and maximum values of two unsorted arrays can be found in O(n+m) steps, it looks like there is at least some room for improvement. That is what we are going to try in the following section.
Partial Sorting Solution
Suppose that we know the median of the first array. We could partition the array around the median in the same way as it is done in QuickSort and similar algorithms. The goal of the partitioning step is to produce partial ordering of the array. All values less than the chosen value (pivot) should be moved towards the beginning of the array. All values greater than the pivot should be moved towards the end of the array. And middle positions should be populated by elements that are equal to the pivot value.
The trick at this point is to partition the second array using exactly the same pivot value. In this way we are producing such state in which whole sections of the arrays are guaranteed to contain disjoint values.
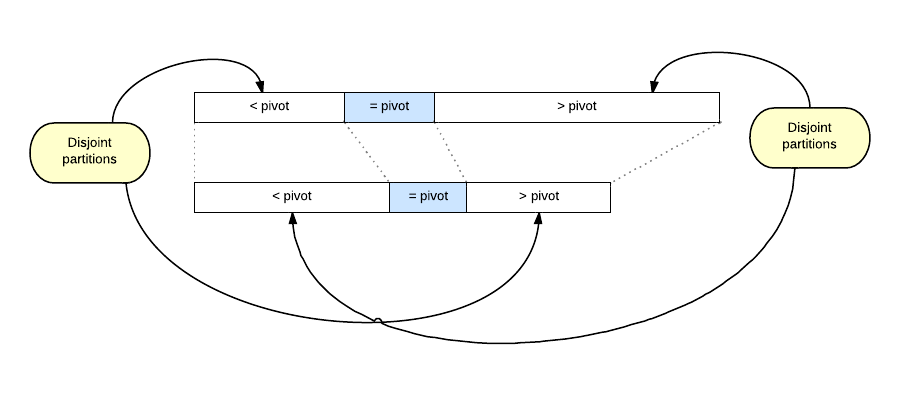
The gain obtained this way is twofold. First, we don't need to compare elements from crossing sections of the arrays: we know that these sections are disjoint and there are no elements that would contribute to the intersection. Second, more important benefit, is that from time to time one of the sections will be empty. In that case the whole corresponding section in the other array can be ignored. That is the real benefit from partially sorting the arrays: parts that are obviously disjoint will quickly be removed from further processing.
Below is the pseudocode for this solution.
function IntersectionPartialSort(a, b, n, m)
-- a - array
-- b - array
-- n - length of a
-- m - length of b
begin
return IntersectionRecursive(a, b, 1, n, 1, m)
end
function IntersectionRecursive(a, b, aStart, aEnd, bStart, bEnd)
-- a - array
-- b - array
-- aStart - first position in a to intersect
-- aEnd - last position in a to intersect
-- bStart - first position in b to intersect
-- bEnd - last position in b to intersect
begin
intersection - resulting array
pivot = MedianOfMedians(a, aStart, aEnd);
Partition(a, aStart, aEnd, pivot, out aPivotStart, out aPivotLen)
Partition(b, bStart, bEnd, pivot, out bPivotStart, out bPivotLen)
-- Find intersection of pivots
for i = 1 to min(aPivotLen, bPivotLen)
append pivot to intersection
-- Recursively solve left partitions
if aPivotStart > aStart AND bPivotStart > bStart then
begin
part = IntersectionRecursive(a, b, aStart, aPivotStart - 1,
bStart, bPivotStart - 1)
append part to intersection
end
-- Recursively solve right partitions
if aPivotStrat + aPivotLen < aEnd AND
bPivotStart + bPivotLen < bEnd then
begin
part = IntersectionRecursive(a, b, aPivotStart + aPivotLen, aEnd,
bPivotStart + bPivotLen, bEnd)
append part to intersection
end
end
function Partition(a, start, end, pivot, out pivotStart, out pivotLen)
-- a - array
-- start - starting position to partition
-- end - ending position to partition
-- pivot - pivot value around which to partition
-- pivotStrat - on output first position at which pivot occurs
-- pivotLen - on output total number of occurrences of pivot
begin
i = start
while i <= end
begin
if a[i] < pivot then
a[start] = a[i]
i = i + 1
start = start + 1
else if a[i] = pivot then
i = i + 1
else
tmp = a[end]
a[end] = a[i]
a[i] = tmp
end = end - 1
end
for i = start to end
a[i] = pivot
pivotStart = start
pivotLen = end - start + 1
end
function MedianOfMedians(a, int start, int finish)
-- a - array
-- strat - starting index from which median is calcuated
-- finish - ending index until which median is calculated
begin
while finish > start + 1
begin
pos = start
for segmentStart = start to finish step 5
begin
segmentEnd = segmentStart + 5
if segmentEnd > end then
segmentEnd = end;
for i = segmentStart to segmentEnd - 1
for j = i + 1 to segmentEnd
if a[i] > a[j] then
begin
tmp = a[i]
a[i] = a[j]
a[j] = tmp
end
middlePos = (segmentStart + segmentEnd) / 2
tmp = a[pos]
a[pos] = a[middlePos]
a[middlePos] = tmp
pos = pos + 1
end
finish = pos;
end
return a[start];
end
Worst case running time of this solution is the same as for full sorting solution: O(nlogn+mlogm). What we are hoping for is improved average running time thanks to stopping condition which ends the processing of parts of the array that do not have an overlapping part in another array.
Implementation
In this section we are providing implementation in C# for full sorting and for partial sorting solution.
using System;
using System.Collections;
using System.Collections.Generic;
namespace Intersection
{
public class Program
{
static List<int> IntersectionPartialSort(int[] a,int[] b)
{
List<int> intersection = new List<int>();
IntersectionRecursive(a, b, 0, a.Length - 1,
0, b.Length - 1, intersection);
return intersection;
}
static void IntersectionRecursive(int[] a,int[] b,
int aStart,int aEnd,
int bStart,int bEnd,
List<int> intersection)
{
int pivot = MedianOfMedians(a, aStart, aEnd);
int aPivotStart;
int aPivotLen;
int bPivotStart;
int bPivotLen;
Partition(a, aStart, aEnd, pivot,
out aPivotStart, out aPivotLen);
Partition(b, bStart, bEnd, pivot,
out bPivotStart, out bPivotLen);
// Find intersection of pivots
for (int i = 0; i < aPivotLen && i < bPivotLen; i++)
intersection.Add(pivot);
// Recursively solve left partitions
if (aPivotStart > aStart && bPivotStart > bStart)
IntersectionRecursive(a, b, aStart, aPivotStart - 1,
bStart, bPivotStart - 1,
intersection);
// Recursively solve right partitions
if (aPivotStart + aPivotLen - 1 < aEnd &&
bPivotStart + bPivotLen - 1 < bEnd)
IntersectionRecursive(a, b, aPivotStart + aPivotLen, aEnd,
bPivotStart + bPivotLen, bEnd,
intersection);
}
static void Partition(int[] a,int start,int end,int pivot,
out int pivotStart, out int pivotLen)
{
int i = start;
while (i <= end)
{
if (a[i] < pivot)
{
a[start++] = a[i++];
}
else if (a[i] == pivot)
{
i++;
}
else
{
int tmp = a[end];
a[end] = a[i];
a[i] = tmp;
end--;
}
}
for (i = start; i <= end; i++)
a[i] = pivot;
pivotStart = start;
pivotLen = end - start + 1;
}
static int MedianOfMedians(int[] a,int start,int end)
{
while (end > start + 1)
{
int pos = start;
for (int segment = start; segment < end; segment += 5)
{
int tmp;
int segmentEnd = segment + 5;
if (segmentEnd > end)
segmentEnd = end;
for (int i = segment; i < segmentEnd - 1; i++)
for (int j = i + 1; j < segmentEnd; j++)
if (a[i] > a[j])
{
tmp = a[i];
a[i] = a[j];
a[j] = tmp;
}
int middlePos = (segment + segmentEnd - 1) / 2;
tmp = a[pos];
a[pos] = a[middlePos];
a[middlePos] = tmp;
pos++;
}
end = pos;
}
return a[start];
}
static List<int> IntersectionFullSort(int[] a,int[] b)
{
Array.Sort(a);
Array.Sort(b);
List<int> intersection = new List<int>();
int i = 0;
int j = 0;
while (i < a.Length && j < b.Length)
{
if (a[i] == b[j])
{
intersection.Add(a[i]);
i++;
j++;
}
else if (a[i] < b[j])
{
i++;
}
else
{
j++;
}
}
return intersection;
}
static List<int> IntersectionIndexing(int[] a,int[] b)
{
List<int> intersection = null;
if (a.Length > b.Length)
{
intersection = IntersectionIndexing(b, a);
}
else
{
Hashtable hash = new Hashtable();
intersection = new List<int>();
for (int i = 0; i < a.Length; i++)
{
if (hash.Contains(a[i]))
hash[a[i]] = (int)hash[a[i]] + 1;
else
hash.Add(a[i], 1);
}
for (int i = 0; i < b.Length; i++)
{
int count = 0;
if (hash.Contains(b[i]))
count = (int)hash[b[i]];
if (count > 1)
{
intersection.Add(b[i]);
hash[b[i]] = count - 1;
}
else if (count == 1)
{
intersection.Add(b[i]);
hash.Remove(b[i]);
}
}
}
return intersection;
}
static int[] CopyArray(int[] a)
{
int[] b = newint[a.Length];
a.CopyTo(b, 0);
return b;
}
static int[] CreateArray(int len,int rangeLow,int rangeHigh)
{
int[] a = newint[len];
for (int i = 0; i < len; i++)
a[i] = _rnd.Next(rangeLow, rangeHigh);
return a;
}
delegate List<int> IntersectionAlgorithm(int[] a,int[] b);
static void RunPerformanceTest()
{
int range = 50000;
int length = 300000;
int repeatsCount = 10;
double[,] timeSpent = new double[3, 101];
IntersectionAlgorithm[] algorithms =
new IntersectionAlgorithm[3]
{
IntersectionFullSort,
IntersectionPartialSort,
IntersectionIndexing
};
for (int repeat = 0; repeat < repeatsCount; repeat++)
{
for (int overlap = 0; overlap <= 100; overlap++)
{
int snap = range * (100 - overlap) 100;
int[] a = CreateArray(length, 0, range);
int[] b = CreateArray(length, snap, range + snap);
for (int alg = 0; alg < algorithms.Length; alg++)
{
int[] aCopy = CopyArray(a);
int[] bCopy = CopyArray(b);
DateTime tsStart = DateTime.UtcNow;
algorithms[alg](aCopy, bCopy);
DateTime tsEnd = DateTime.UtcNow;
timeSpent[alg, overlap] +=
(tsEnd - tsStart).TotalMilliseconds;
}
}
}
for (int percent = 0; percent <= 100; percent++)
{
Console.Write("{0,4}%", percent);
for (int i = 0; i < 3; i++)
Console.Write("\t{0:0}",
timeSpent[i, percent] repeatsCount);
Console.WriteLine();
}
}
static int[] ReadArray()
{
Console.Write("Enter array elements (ENTER to exit): ");
string[] elements =
Console
.ReadLine()
.Split(new char[] { ' ' },
StringSplitOptions.RemoveEmptyEntries);
int[] a = null;
if (elements.Length > 0)
{
a = new int[elements.Length];
for (int i = 0; i < elements.Length; i++)
a[i] =int.Parse(elements[i]);
}
return a;
}
static void PrintList(List<int> list)
{
foreach (int value in list)
Console.Write("{0,4}", value);
Console.WriteLine();
}
static void Main(string[] args)
{
Console.Write("Execute performance test? (y/n) ");
if (Console.ReadLine().ToLower() == "y")
RunPerformanceTest();
while (true)
{
int[] a = ReadArray();
if (a == null)
break;
int[] b = ReadArray();
if (b == null)
break;
List<int> intersection = IntersectionPartialSort(a, b);
Console.WriteLine("Array intersection is:");
PrintList(intersection);
}
}
static Random _rnd = new Random();
}
}
Demonstration
When this application is run, it produces the following output:
Execute performance test? (y/n) n
Enter array elements (ENTER to exit): 3 1 2 3 4 2 3
Enter array elements (ENTER to exit): 2 3 6 2 5 2 2 3
Array intersection is: 2 2 3 3
Enter array elements (ENTER to exit):
Output shows that partial sorting algorithm correctly identifies values that appear in both input arrays. This is not a surprise. But what might surprise many is the diagram that follows.
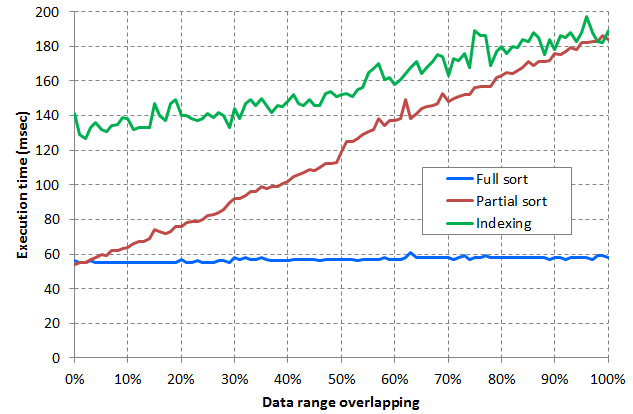
Picture above shows running times of three intersection algorithms. Horizontal axis indicates how much data from the two arrays are overlapping. For example, if first array contains random data in range 1-1000 and second array random data in range 701-1700, then overlapping is 30%. The first line represents full sorting algorithm with asymptotic complexity O(nlogn). Second line represents partial sorting algorithm with same complexity O(nlogn) and optimized value selection and. Finally, the third line represents indexing algorithm with complexity O(n). While asymptotic complexity indicates that running time might be lower for indexing algorithm, this solution actually performs much worse than solutions with higher complexity.
There are several reasons that lead to this consequence. Probably most important one has to do with CPU architecture. Here is the very short explanation of what happens when we iterate through two arrays simultaneously, as it is done in the IntersectionFullSort. (The fact that arrays are sorted plays no role in this analysis.) What CPU internally does when it accesses an array element is to immediately request values from operating memory which immediately follows the accessed location. This is done because there is expectation that application might ask for the nearby data soon, which is absolutely true when iterating through an array. These prefetched values are stored in CPU cache - small but very fast portion of memory, located physically near or on the same chip with CPU. Accessing data from cache is multiple times faster than reading the same data from the operating memory.
Now let's turn to the indexing solution. It first adds all elements of one array to a hash table. Then it iterates through the other array and queries the hash table for each of the values it encounters. While doing that, function pays heavy penalty by not being able to profit on spatial locality of data. Values are scattered around the hash table (that is how hash table works in the first place). Result is that any given value is likely not to be found in CPU cache. This is simply because portion of the hash table which contains the requested value is probably not very near to any other part visited recently.
These processes are very complex in their nature and it is often hard to foresee their effects. But when comparing time needed to iterate through an array with time needed to query the hash table same number of times, result becomes much more predictable. Simple iteration takes advantage of using CPU cache and executes several times faster than the competing hashing algorithm.
Conclusion is that constant factor in indexing solution is so large that it makes the whole function slower than any other, despite the optimistic asymptotic complexity.
But what about the partial sorting solution? It makes less comparisons searching for common values, thanks to its ability to discard whole sections of arrays. But in order to discover which sections can be discarded, this function performs quite a lot of analysis: finding a good pivot and partitioning arrays. Result is again high constant factor, making this function consistently slower than the full sorting solution.
What happened here is what often happens when theory hits the reality. Execution time is not the same as asymptotic complexity. It is not even proportional to the expression depicted by the asymptotic complexity, but the proportion varies with dimension of data set at hand. Shortest and most elegant solution has won the competition. It relies on sorting function borrowed from the framework, function which is beyond any doubt highly optimized.
Moral of the story is that most optimized algorithm is not necessarily the fastest one. It's often the other way around. Short code with simple flow, like iteration, which relies on built-in functions is often the fastest one in practice, despite the slight handicap in terms of asymptotic complexity.
If you wish to learn more, please watch my latest video courses

Beginning Object-oriented Programming with C#
In this course, you will learn the basic principles of object-oriented programming, and then learn how to apply those principles to construct an operational and correct code using the C# programming language and .NET.
As the course progresses, you will learn such programming concepts as objects, method resolution, polymorphism, object composition, class inheritance, object substitution, etc., but also the basic principles of object-oriented design and even project management, such as abstraction, dependency injection, open-closed principle, tell don't ask principle, the principles of agile software development and many more.
More...

Design Patterns in C# Made Simple
In this course, you will learn how design patterns can be applied to make code better: flexible, short, readable.
You will learn how to decide when and which pattern to apply by formally analyzing the need to flex around specific axis.
More...

Refactoring to Design Patterns
This course begins with examination of a realistic application, which is poorly factored and doesn't incorporate design patterns. It is nearly impossible to maintain and develop this application further, due to its poor structure and design.
As demonstration after demonstration will unfold, we will refactor this entire application, fitting many design patterns into place almost without effort. By the end of the course, you will know how code refactoring and design patterns can operate together, and help each other create great design.
More...

Mastering Iterative Object-oriented Development in C#
In four and a half hours of this course, you will learn how to control design of classes, design of complex algorithms, and how to recognize and implement data structures.
After completing this course, you will know how to develop a large and complex domain model, which you will be able to maintain and extend further. And, not to forget, the model you develop in this way will be correct and free of bugs.
More...
About

Zoran Horvat is the Principal Consultant at Coding Helmet, speaker and author of 100+ articles, and independent trainer on .NET technology stack. He can often be found speaking at conferences and user groups, promoting object-oriented and functional development style and clean coding practices and techniques that improve longevity of complex business applications.
Elsewhere
Video Courses
- Making Your C# Code More Object-oriented
- Beginning Object-oriented Programming with C#
- Collections and Generics in C#
- Design Patterns in C# Made Simple
- Refactoring to Design Patterns
- Mastering Iterative Object-oriented Programming in C#
- Making Your C# Code More Functional
- Making Your Java Code More Object-oriented
- Writing Purely Functional Code in C#
- Tactical Design Patterns in .NET: Creating Objects
- Tactical Design Patterns in .NET: Control Flow
- Tactical Design Patterns in .NET: Managing Responsibilities
- Advanced Defensive Programming Techniques
- Writing Highly Maintainable Unit Tests
- Improving Testability Through Design
Articles
- Here is Why Calling a Virtual Function from the Constructor is a Bad Idea
- What Makes List<T> So Efficient in .NET?
- Nondestructive Mutation and Records in C#
- Understanding Covariance and Contravariance of Generic Types in C#
- Using Record Types in C#
- Unit Testing Case Study: Calculating Median
- More...