How to Organize Repository Interfaces to Support CQRS Architecture
by Zoran Horvat
Command Query Responsibility Segregation (CQRS) is a common architectural style in modern software, especially in distributed systems. The idea behind CQRS is that one model should be used to modify the data and another model to query the data.
Even if we are operating on a single database, it makes sense to separate command models from view models. Doing so will simplify implementation, because these two models are serving a different purpose.
Understanding Differences between Command and Query Models
Command model is heavyweight, loaded with domain logic. It comes with high construction cost, thanks to dependencies and relations to other models. Command model allows us to perform operations that belong to domain logic. It relies on encapsulation to make better use of object-oriented concepts, leading to maintainable, flexible and more powerful domain layer implementation.
Query model is lightweight. Its only purpose is to convey information to the presentation layer in the most straightforward way we can find. View models normally load their content from a view, rather than a table. It makes sense to perform all the joins and projections in the database itself, and then expose the data to the query stack in a plain tabular form. That would simplify the application and make it easier to load view models and transfer them towards the presentation.
Fine-Tuning CQRS Architecture
From this analysis, it comes that CQRS architecture does not necessarily require total separation of command and query stacks. In medium-sized applications, in monolithic applications that operate on a single database, it is still possible to develop in spirit of CQRS. All it takes is to make a clear distinction between operations that are changing the data and operations that are querying the data. In order to implement those two kinds of operations, we need to have classes that are dealing with commands kept separate from classes that are dealing with queries.
And when it comes to constructing model objects from the database, it turns that construction process is different for command models than for query models. For one thing, command models support such operations as Add or Delete, which make no sense when talking about query models.
Adding Repositories to the Picture
If we suppose that the underlying implementation of the infrastructure relies on Repository pattern, we can then make clear distinction between repositories that support command models and repositories that merely feed query models. This distinction is important because interface of the repository must be able to convey its purpose clearly. We don’t want to be able to attempt to save changes on a query repository.
I have been in position to define repository structure from scratch on a recent project. There was a clear distinction between command and query models, although command and query stacks were not entirely divided. It was a single service, with a single database, and with command and query responsibilities kept separate.
During the analysis, we found that consumers have certain requirements on repositories. Here is the list of conditions under which repositories were used:
- Both Command and Query stacks need to query the database – They both need access to query repositories.
- Command stack needs to be able to wrap operations in a transaction – This means that both query and command repositories need to support transactions.
- Query stack needs not use transactions – This means that use of transactions must be optional in repositories.
- Command stack will add new objects to the database and delete existing ones – This means that command repository will have to expose such methods as Add and Remove.
- Both Command and Query stack need to be able to construct complex queries – Since both stacks will use query repositories for the purpose, this indicates that the repository will expose a Query method which returns IQueryable, rather than IEnumerable or so.
- Command stack will only modify one object at the time – This indicates that command repository should expose a method such as GetById, to fetch one instance of the model.
- Command stack will have to save all changes in one transaction – Since only the command repositories will have anything to save, they will be the only ones to expose a Save method.
Proposed Hierarchy of Repository Interfaces
As the result of this analysis, below is the entire diagram showing the hierarchy of interfaces which were implemented in the end.
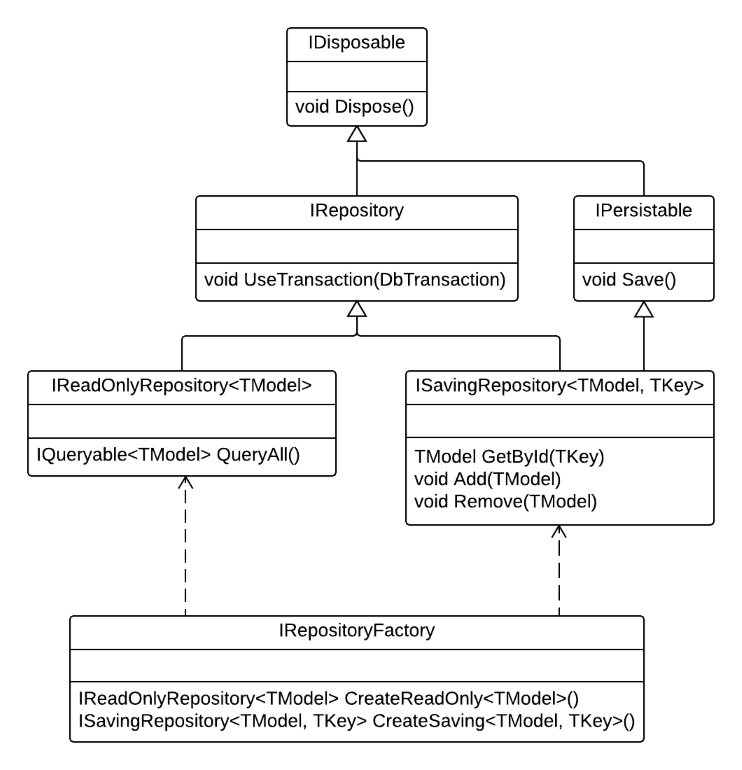
With this organization of interfaces, we could easily support all operations that were required:
- Querying the model in the Query stack – Use CreateReadOnly() on repository factory object to get hold of the IReadOnlyRepository<TModel>; then use QueryAll() method on the repository to construct a desired query.
- Creating new object in the Command stack – Use CreateSaving() method on repository factory object to get hold of the ISavingRepository object; then use Add() method to add new object and save changes using the Save() method.
- Modifying existing object in the Command stack – Use CreateReadOnly() method of the repository factory to construct querying repository and use its QueryAll() method to discover the object to modify; then use CreateSaving() method on repository factory to get hold of the ISavingRepository object and then load command model through its GetById() method; call Save() on command repository after changes were made to the command model.
- Deleting existing object in the Command stack – Use CreateReadOnly() method of the repository factory to construct querying repository and use its QueryAll() method to discover the object to delete; then use CreateSaving() method on repository factory to get hold of the ISavingRepository object and load command model through its GetById() method; submit the loaded model to the Remove() method and then call Save() on the command repository.
In addition to basic CRUD scenarios, this structure also allows the command stack to wrap entire process in a transaction, because both read-only and read-write repositories expose UseTransaction method.
Command stack can save changes in all subordinate repositories by looking at those that implement IPersistable and then calling their Save() method. This simplifies the operation, because the consumer doesn’t have to know which repositories are operating on database tables and which on the views – it is the IPersistable non-generic interface which gives them out.
Similarly, the consumer doesn’t have to know the underlying model in order to wrap operations in a transaction. UseTransaction() method is implemented at the level of general IRepository, which is also not generic. This means that transaction management can be safely separated from model management and it can be turned into a general operation which doesn’t know the underlying model.
Summary
In this article we have seen one possible organization of repository interfaces which supports command-query separation.
It is by far not the best possible organization, and even more than that it is not the only possible organization. But it has stood the test of time in a real-world project, and therefore I could recommend you to take it into account in your projects.
You can use this design either as a ready-made solution, or as a base from which another custom design could be derived, such that you can which better suits your needs.
If you wish to learn more, please watch my latest video courses

Beginning Object-oriented Programming with C#
In this course, you will learn the basic principles of object-oriented programming, and then learn how to apply those principles to construct an operational and correct code using the C# programming language and .NET.
As the course progresses, you will learn such programming concepts as objects, method resolution, polymorphism, object composition, class inheritance, object substitution, etc., but also the basic principles of object-oriented design and even project management, such as abstraction, dependency injection, open-closed principle, tell don't ask principle, the principles of agile software development and many more.
More...

Design Patterns in C# Made Simple
In this course, you will learn how design patterns can be applied to make code better: flexible, short, readable.
You will learn how to decide when and which pattern to apply by formally analyzing the need to flex around specific axis.
More...

Refactoring to Design Patterns
This course begins with examination of a realistic application, which is poorly factored and doesn't incorporate design patterns. It is nearly impossible to maintain and develop this application further, due to its poor structure and design.
As demonstration after demonstration will unfold, we will refactor this entire application, fitting many design patterns into place almost without effort. By the end of the course, you will know how code refactoring and design patterns can operate together, and help each other create great design.
More...

Mastering Iterative Object-oriented Development in C#
In four and a half hours of this course, you will learn how to control design of classes, design of complex algorithms, and how to recognize and implement data structures.
After completing this course, you will know how to develop a large and complex domain model, which you will be able to maintain and extend further. And, not to forget, the model you develop in this way will be correct and free of bugs.
More...
About

Zoran Horvat is the Principal Consultant at Coding Helmet, speaker and author of 100+ articles, and independent trainer on .NET technology stack. He can often be found speaking at conferences and user groups, promoting object-oriented and functional development style and clean coding practices and techniques that improve longevity of complex business applications.
Elsewhere
Video Courses
- Making Your C# Code More Object-oriented
- Beginning Object-oriented Programming with C#
- Collections and Generics in C#
- Design Patterns in C# Made Simple
- Refactoring to Design Patterns
- Mastering Iterative Object-oriented Programming in C#
- Making Your C# Code More Functional
- Making Your Java Code More Object-oriented
- Writing Purely Functional Code in C#
- Tactical Design Patterns in .NET: Creating Objects
- Tactical Design Patterns in .NET: Control Flow
- Tactical Design Patterns in .NET: Managing Responsibilities
- Advanced Defensive Programming Techniques
- Writing Highly Maintainable Unit Tests
- Improving Testability Through Design
Articles
- Here is Why Calling a Virtual Function from the Constructor is a Bad Idea
- What Makes List<T> So Efficient in .NET?
- Nondestructive Mutation and Records in C#
- Understanding Covariance and Contravariance of Generic Types in C#
- Using Record Types in C#
- Unit Testing Case Study: Calculating Median
- More...