How to Handle Exceptions from Background Worker Thread in .NET
by Zoran Horvat
Introduction
Using threads or BackgroundWorker class (System.ComponentModel.Component namespace) is a common method used to improve responsiveness in .NET applications of all kinds. On the other hand, structured exception handling is a common method of passing exceptional errors and conditions that could not be foreseen to callers. But these two concepts do not work together by default. Exceptions raised within the worker thread are not passed on to the thread which has initiated the work, which turns out to be the entity most interested in processing results including exceptions thrown. This article provides explanations why threads and exceptions work in this way, and then provides one sound solution to the problem. Note that solution presented below should be followed as a pattern, rather than a ready-made code. But even with that restriction, it is a handy way out of the trouble.
In the sections that follow we will first address the way in which structured exception handling works. Then we will observe it when applied to multithreaded applications to explain why exceptions cannot be passed between threads natively. Finally, solution to the problem will be revealed, including some typical alternatives.
Throughout the text, we will apply all that is said to a simple practical example. Background worker will be used to perform a series of algebraic operations. These operations will have a bad habit of breaking down from time to time, resulting in exceptions being thrown from inside the background worker. Task in front of us is to enable the caller, the one who has asked for the operation, to catch and handle those exceptions.
Problem Statement
First we will define the expected behavior of the system. Namely, suppose that we already have a piece of software which performs one specific operation. Then, at some point later, we decide to offload that operation to a background worker thread. What we basically expect is that remaining of our software is not changed if exception occurs. Let's examine this closer on an example.
In our application we will solve the following problem. A person driving a car travels several sections of the road at different speeds. Just as an example, suppose that section of length 10 km car travels at speed 36 km/h (10 m/s); next section of length 21 km car travels at speed 50.4 km/h (14 m/s). Task is to produce average speed. We can solve this problem manually by observing that first 10 km of the road require 1000 seconds, while the second part of the road requires 1500 seconds, which makes total of 2500 seconds to travel. Average speed is calculated as combined road length divided by combined time intervals, which is 31 km divided by 2500 seconds, making 12.4 m/s or something like 44.64 km/h on average.
In general case, if road is divided into n segments travelled at n distinct speeds, then average speed is:
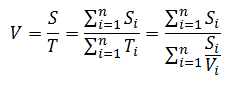
Here is the code which implements this formula:
public float TotalTravelTime(float[] distances, float[] speeds)
{
float time = 0.0F;
for (int i = 0; i < distances.Length; i++)
time += distances[i] / speeds[i];
return time;
}
public float AverageSpeed(float[] distances, float[] speeds)
{
float distance = 0.0F;
for (int i = 0; i < distances.Length; i++)
distance += distances[i];
float time = TotalTravelTime(distances, speeds);
float speed = distance / time;
return speed;
}
We can even try this code on the example above:
float[] distances = new float[] { 10.0F, 21.0F };
float[] speeds = new float[] { 36.0F, 50.4F };
float speed = AverageSpeed(distances, speeds);
Console.WriteLine(speed);
This piece of code prints out value 44.64, exactly as we have calculated manually. (Note that measuring unit conversions are not required as long as both distances and speeds are expressed in the same and consistent units: km and km/h, m and m/s, etc.)
Now that we have a basic solution, we want to add negative branches to it, and that is to test conditions that would cause the code to break apart. Such conditions will be detected and appropriate exceptions thrown so that caller can act upon them. Here are the modified functions:
public float TotalTravelTime(float[] distances, float[] speeds)
{
float time = 0.0F;
if (distances == null)
throw new System.ArgumentNullException("distances");
else if (speeds == null)
throw new System.ArgumentNullException("speeds");
else if (distances.Length != speeds.Length)
throw new System.ArgumentException(
string.Format("Number of segment lengths ({0}) must be equal to number of speeds ({1}).",
distances.Length, speeds.Length));
for (int i = 0; i < distances.Length; i++)
{
if (speeds[i] < 0)
throw new System.ArgumentException(
string.Format("Cannot accept negative speed ({0}).", speeds[i]),
string.Format("speeds[{0}]", i));
else if (speeds[i] == 0)
throw new System.DivideByZeroException("Cannot accept zero speed");
time += distances[i] / speeds[i];
}
return time;
}
public float AverageSpeed(float[] distances, float[] speeds)
{
float distance = 0.0F;
if (distances == null)
throw new System.ArgumentNullException("distances");
for (int i = 0; i < distances.Length; i++)
{
if (distances[i] < 0)
throw new System.ArgumentException(
"Cannot accept negative distance.",
string.Format("distances[{0}]", i));
distance += distances[i];
}
float time = TotalTravelTime(distances, speeds);
if (time == 0) // This happens if distances and speeds arrays have dimension zero
throw new System.DivideByZeroException("Total travelling time is zero.");
float speed = distance / time;
return speed;
}
It's not hard to notice that functions have become significantly longer after error testing has been added – a common state of affairs in practice. But caller does not suffer that much, although it changes appropriately. The calling code needs only to know (and that is communicated to its developer through the documentation) the list of exceptions thrown by the functions used. In this case, exceptions to handle are:
- System.DivideByZeroException – when input data are such that division by zero would occur should the arithmetic operations be executed as planned,
- System.ArgumentNullException – when one or both input vectors are null,
- System.ArgumentException – when contents of input vectors is incorrect, like negative speeds of distances, number of distances doesn't match corresponding number of travelling speeds.
In all cases listed, functions are unable to produce valid output and therefore they decide to throw exceptions to get out of the trouble. Here is the modified code which calls the AverageSpeed function:
float[] distances = new float[] { 10.0F, 21.0F };
float[] speeds = new float[] { 36.0F, 50.4F };
try
{
float speed = AverageSpeed(distances, speeds);
Console.WriteLine(speed);
}
catch (System.ArgumentNullException exNull)
{
Console.WriteLine("Argument was null: {0}", exNull.ParamName);
}
catch (System.ArgumentException exArg)
{
Console.WriteLine("Error in argument {0}: {1}", exArg.ParamName, exArg.Message);
}
catch (System.DivideByZeroException)
{
Console.WriteLine("Division by zero.");
}
Caller's job was to catch exceptions thrown by the functions called and to handle them accordingly.
And now comes the point. We want to offload the calculation to a background worker thread. Here is the class (with bodies omitted for functions already provided above) which uses background worker to calculate the average speed:
using System;
using System.ComponentModel;
namespace SpeedCalculator
{
class Calculator
{
public float TotalTravelTime(float[] distances, float[] speeds) { ... }
public float AverageSpeed(float[] distances, float[] speeds) { ... }
public void Calculate(float[] distances, float[] speeds)
{
BackgroundWorker worker = new BackgroundWorker();
worker.DoWork += new DoWorkEventHandler(worker_DoWork);
worker.RunWorkerCompleted += new RunWorkerCompletedEventHandler(worker_RunWorkerCompleted);
_completedEvent = new System.Threading.ManualResetEvent(false);
worker.RunWorkerAsync(new float[][] { distances, speeds });
// Do some lengthy work
_completedEvent.WaitOne();
Console.WriteLine(_calculatedSpeed);
}
private void worker_DoWork(object sender, DoWorkEventArgs e)
{
float[][] argument = (float[][])e.Argument;
float[] distances = argument[0];
float[] speeds = argument[1];
float speed = AverageSpeed(distances, speeds);
e.Result = speed;
}
private void worker_RunWorkerCompleted(object sender, RunWorkerCompletedEventArgs e)
{
_calculatedSpeed = (float)e.Result;
_completedEvent.Set();
}
private float _calculatedSpeed;
private System.Threading.ManualResetEvent _completedEvent;
}
}
In this case, arithmetical part of the program, called from function worker_DoWork, executes on a separate thread rather than on the thread on which Calculate function executes. Once background worker completes its role, it sets the manual-reset event so to notify its parent that the result is stored in its place.
But now, we have completely lost the exception handling part. We could (and should have done it) handle exceptions in the worker_DoWork function, but again that would have no impact on the place in which background worker was initialized. The original caller, and party which expects the result of the calculation for its further work, knows nothing about events that might have gone wrong in the meanwhile. Even worse, result that it reads may as well be incorrect because calculation was given up. So we need to do something to see that calling thread receives exceptions that have been thrown during the calculation.
How Does Structured Exception Handling Work
To understand why exceptions are not passed between threads, we first need to take a look at structured exception handling implementation itself. Here are the details.
To call a function, one has to tell which is the function it desires and to pass its argument values. Then, some time later, when function exits, caller needs to pick up the return value. Apart from these operations, caller is oblivious of the whole bunch of operations performed to make this operational. Under the hood, calling a function means to create so-called stack frame, which is a set of consecutive memory locations on top of the dedicated stack – the call stack. Stack frame contains all fields that are required to call the function, allow it to execute, and then to return back to the place from which it was called, passing the return value there.
In its simplest form, stack frame consists of (in order of appearance): method arguments starting with implicit this pointer, return address, and then local variables of the method which is called. Once the method execution completes, local variables are removed from stack, exposing the return address. This address in turn is taken into Program Counter, special CPU register which points to next instruction to execute, which conveniently falls into the function from which the call was made. After that, arguments are popped off from the stack. With its last breath, the called function leaves return value on the call stack to be picked up by the caller.
The following picture shows contents of the call stack when AverageSpeed is called from the worker_DoWork method, and then it calls TotalTravelTime. Three stack frames are pushed to call stack so that control can be returned to each of the callers when return statement is reached. Note how arguments and return address are pushed to stack at the bottom of each of the stack frames. Remaining of each stack frame is occupied by local variables declared inside the method called. Each nested calling of methods, including recursive calls, causes new stack frame to be pushed to the top of the call stack. As soon as a method returns, its corresponding frame is popped off from the call stack as it is not needed any more. In this way, call stack keeps the whole path of nested calls from the program's entry point all until currently executed statement.
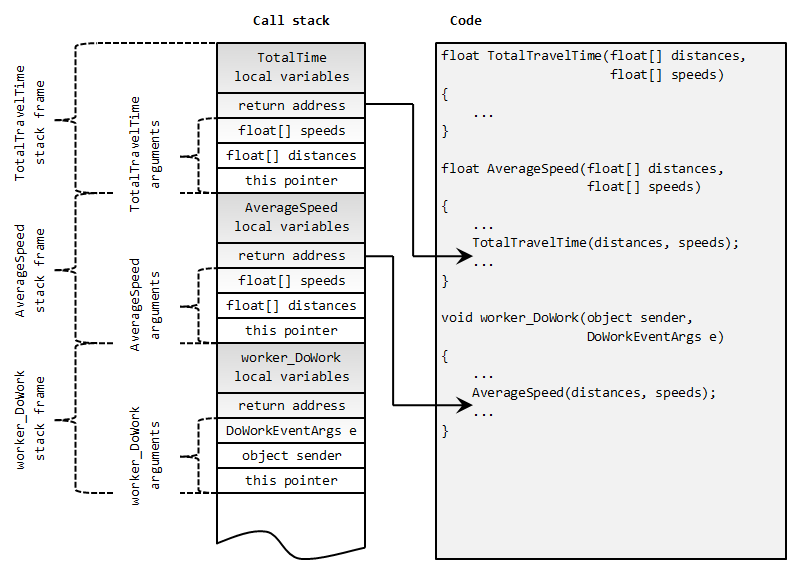
Now that we have outlined normal program execution, we are ready to cover the topic of exceptions. In shortest, throwing an exception causes execution to jump to the nearest catch block for the type of exception thrown. But term nearest in this case requires a little bit more of explanation. Simplest case is the one in which enclosing try...catch block is in the same method in which throw statement has been executed. In that case execution instantly jumps to that catch statement and problems are resolved. However, if appropriate catch block is not part of the current method, then call stack must be unfolded, one stack frame at a time, until execution point occurs inside appropriate try…catch block. This is very important to understand, as that is how exception gets routed to the catch block of the nearest enclosing try…catch of appropriate type.
In case of our arithmetical functions, when System.ArgumentNullException is thrown from inside TotalTravelTime function, the nearest enclosing try...catch block which catches this type of exception is looked for. TotalTravelTime method does not catch exceptions, so its stack frame will be popped off from the call stack. Same destiny awaits the AverageSpeed method. And so the worker_DoWork stack frame is reached. At this point we can imagine that worker_DoWork actually catches System.ArgumentNullException, which means that execution will continue from the catch block for that exception. In reality, worker_DoWork does not handle exceptions and thus exception continues to unfold the call stack further – into gray area beneath the BackgroundWorker, which we are now about to start discovering.
Structured Exception Handling in Multithreaded Environment
When an exception is raised on a thread, but not handled in the thread procedure, it pops up. It is as simple as that. And "up" is the system – those parts of .NET runtime which have started the thread and actually invoked our custom thread procedure. Keep in mind that there is always a function which has called custom thread procedure – call stack doesn't start with custom code, not even in case of the main function! So when call stack for our thread unfolds, and all stack frames related to custom functions are popped up, another stack frame is revealed which belongs to a function from .NET runtime. That function is responsible to catch all exceptions, so that framework doesn't break down if custom code forgets to catch its own exceptions.
But this leads to next question: What happens with such exceptions? (On a related note, term "user unhandled exception" is applied to exceptions which are not handled in custom code.) Well, the answer to the question is in another question: What happens to whom? Unhandled exception on a custom thread will break the application down – that's what happens to the application. It will not break the runtime, though – that's what happens to the rest of the system. Only our process will die an ugly death, leaving the trace of its fall in system's Event Log. This is done thanks to .NET runtime, which actually handles the exception that has bubbled up from custom thread procedure, but only to write it down in Event Log and do some other cleanup work. Runtime will however not try to keep our application alive.
This is probably a good place to tell that every thread has its own call stack. Therefore, if the thread who started a background operation tries to handle exceptions it would catch nothing. Exceptions are thrown on background worker thread's call stack and its own stack frames are unfolded. In case that exception is not caught on that call stack, it would pop up into the .NET runtime's part of the call stack and ultimately cause application to fail. The only way out is to catch all exceptions in each thread procedure with no excuses. What to do with the exception caught is more of a design decision. In one case we might ignore exceptions. In another, we might remember them in a specific variable and let other threads see them in that way. The latter approach is appreciated in most of the practical cases because exception can then be examined by the thread which has requested asynchronous operation.
Exception Handling with BackgroundWorker
Unhandled exception from BackgroundWorker's DoWork event will not break the application. This is so thanks to the fact that BackgroundWorker itself is positioned on call stack between custom implementation of the DoWork event handler and lower regions occupied by the .NET runtime. Therefore BackgroundWorker is in position to actually handle the exception and save the application from breakdown. What it does is to catch whichever the exception occurs, store it in RunWorkerCompletedEventArgs object and pass it on to the RunWorkerCompleted event. What happens next is that RunWorkerCompleted event handler receives event arguments and then it can pick up the exception from their Error property. Typical implementation of the RunWorkerCompleted event handler looks like this:
private void worker_RunWorkerCompleted(object sender, RunWorkerCompletedEventArgs e)
{
if (e.Error != null)
Console.WriteLine("Operation failed with error: {0}", e.Error.Message);
else if (e.Cancelled)
Console.WriteLine("Operation was cancelled.");
else
Console.WriteLine("Asynchronous operation completed with result: {0}", e.Result);
}
Off course, Console printouts should be replaced with something more useful. But this piece of code shows the point – we are first testing whether error has occurred by reading the Error property; if no errors, then we test whether operation was cancelled using the Cancelled property; only when that test is passed we can access the Result property to read the actual operation outcome.
In our example with average speed calculator we are storing the result into another variable, so that main thread can retrieve it. This gives us the idea to store the exception in a separate variable as well, making it available to the main thread along with the result. Here is the code:
private void worker_RunWorkerCompleted(object sender, RunWorkerCompletedEventArgs e)
{
if (e.Error != null)
_error = e.Error;
else if (e.Cancelled)
_cancelled = true;
else
{
_cancelled = false;
_error = null;
_calculatedSpeed = (float)e.Result;
}
_completedEvent.Set();
}
private bool _cancelled;
private System.Exception _error;
private float _calculatedSpeed;
private System.Threading.ManualResetEvent _completedEvent;
This is sufficient to pass all the information from the worker thread to the main thread. Now function which calculates the speed by offloading it to worker thread may look like this:
public float Calculate(float[] distances, float[] speeds)
{
BackgroundWorker worker = new BackgroundWorker();
worker.DoWork += new DoWorkEventHandler(worker_DoWork);
worker.RunWorkerCompleted += new RunWorkerCompletedEventHandler(worker_RunWorkerCompleted);
_completedEvent = new System.Threading.ManualResetEvent(false);
worker.RunWorkerAsync(new float[][] { distances, speeds });
// Do some lengthy work
_completedEvent.WaitOne();
if (_error != null)
throw _error;
// We're not cancelling the operation so we can safely assume that _cancelled is false
return _calculatedSpeed;
}
Observe what happens if operation has failed with exception. Implementation which relies on results of the background operation, simply rethrows the same exception. It is up to the ultimate caller to catch and process it. In this way, we have transferred the exception from background worker thread to main thread. In other words, we have moved it to main thread's call stack and there it could be caught as if it was originally thrown there.
The only detail to keep in mind here is that exception's StackTrace property will receive new value – the throw statement will cause stack trace of the exception to be rebuilt so that it depicts exact spot of that statement, rather than the statement which originally threw the exception on the worker thread. Beware of this, as you won't be able to pinpoint the original error after rethrowing it. For this reason, it is often better to wrap the original exception in new one:
throw new System.Exception("Error occurred on worker thread", _error);
In this case complete information about the original error would be retained, but then type of the exception would be lost. Suppose that our Calculate function is called like this:
float[] distances = new float[] { 10.0F, 21.0F };
float[] speeds = new float[] { 36.0F, 50.4F };
try
{
calc.Calculate(distances, speeds);
}
catch (System.ArgumentNullException ex)
{
}
This code would catch nothing, because exception type which used to be System.ArgumentNullException is now System.Exception. This effect must be taken into account when offloading work to background thread. If calling code expects old types of exceptions, like System.ArgumentNullException, then there are not many options left to us: Either to rethrow the exception received from background worker (and thus lose the stack trace), or to test the exception's type and then to throw new exception of the same type.
Custom Implementation
In case that we do not use BackgroundWorker, but rather create own thread, things don't change much. Thread procedure would have to catch all exceptions and then to pass them to a variable so that main thread can read it. Here is implementation of our average speed calculator with custom thread.
using System;
namespace SpeedCalculator
{
class Calculator
{
public float TotalTravelTime(float[] distances, float[] speeds) { ... }
public float AverageSpeed(float[] distances, float[] speeds) { ... }
public float Calculate(float[] distances, float[] speeds)
{
_completedEvent = new System.Threading.ManualResetEvent(false);
System.Threading.Thread thread = new System.Threading.Thread(ThreadProc);
object[] args = new object[] { this, distances, speeds };
// this pointer is required to leave the result!
thread.Start((object)args);
// Do some lengthy work
_completedEvent.WaitOne();
if (_error != null)
throw _error;
return _calculatedSpeed;
}
private static void ThreadProc(object args)
{
object[] array = (object[])args;
Calculator thisPtr = (Calculator)array[0];
float[] distances = (float[])array[1];
float[] speeds = (float[])array[2];
try
{
float result = thisPtr.AverageSpeed(distances, speeds);
thisPtr._error = null;
thisPtr._calculatedSpeed = result;
}
catch (System.Exception ex)
{
thisPtr._error = ex;
}
thisPtr._completedEvent.Set();
}
private bool _cancelled;
private System.Exception _error;
private float _calculatedSpeed;
private System.Threading.ManualResetEvent _completedEvent;
}
}
It's easy to see that this custom impementation is almost the same as when BackgroundWorker was used. Generally, such simple tasks are not those for which BackgroundWorker was designed. BackgroundWorker is useful only when cancellation and/or progress indication is required.
Conclusion
In this article we have demonstrated how to preserve and pass exceptions across thread boundaries. Thread on which exception occurs is so often unable to process it because that would be outside of its scope. It is up to the caller to decide what to do in every exceptional case. But when caller is on a different thread, then it cannot catch the exception. Therefore, techniques like those described in this article must be employed to transfer the exception object to the calling thread, where it can be processed according to application's needs.
If you wish to learn more, please watch my latest video courses

Beginning Object-oriented Programming with C#
In this course, you will learn the basic principles of object-oriented programming, and then learn how to apply those principles to construct an operational and correct code using the C# programming language and .NET.
As the course progresses, you will learn such programming concepts as objects, method resolution, polymorphism, object composition, class inheritance, object substitution, etc., but also the basic principles of object-oriented design and even project management, such as abstraction, dependency injection, open-closed principle, tell don't ask principle, the principles of agile software development and many more.
More...

Design Patterns in C# Made Simple
In this course, you will learn how design patterns can be applied to make code better: flexible, short, readable.
You will learn how to decide when and which pattern to apply by formally analyzing the need to flex around specific axis.
More...

Refactoring to Design Patterns
This course begins with examination of a realistic application, which is poorly factored and doesn't incorporate design patterns. It is nearly impossible to maintain and develop this application further, due to its poor structure and design.
As demonstration after demonstration will unfold, we will refactor this entire application, fitting many design patterns into place almost without effort. By the end of the course, you will know how code refactoring and design patterns can operate together, and help each other create great design.
More...

Mastering Iterative Object-oriented Development in C#
In four and a half hours of this course, you will learn how to control design of classes, design of complex algorithms, and how to recognize and implement data structures.
After completing this course, you will know how to develop a large and complex domain model, which you will be able to maintain and extend further. And, not to forget, the model you develop in this way will be correct and free of bugs.
More...
About

Zoran Horvat is the Principal Consultant at Coding Helmet, speaker and author of 100+ articles, and independent trainer on .NET technology stack. He can often be found speaking at conferences and user groups, promoting object-oriented and functional development style and clean coding practices and techniques that improve longevity of complex business applications.
Elsewhere
Video Courses
- Making Your C# Code More Object-oriented
- Beginning Object-oriented Programming with C#
- Collections and Generics in C#
- Design Patterns in C# Made Simple
- Refactoring to Design Patterns
- Mastering Iterative Object-oriented Programming in C#
- Making Your C# Code More Functional
- Making Your Java Code More Object-oriented
- Writing Purely Functional Code in C#
- Tactical Design Patterns in .NET: Creating Objects
- Tactical Design Patterns in .NET: Control Flow
- Tactical Design Patterns in .NET: Managing Responsibilities
- Advanced Defensive Programming Techniques
- Writing Highly Maintainable Unit Tests
- Improving Testability Through Design
Articles
- Here is Why Calling a Virtual Function from the Constructor is a Bad Idea
- What Makes List<T> So Efficient in .NET?
- Nondestructive Mutation and Records in C#
- Understanding Covariance and Contravariance of Generic Types in C#
- Using Record Types in C#
- Unit Testing Case Study: Calculating Median
- More...